

The good, the bad, and the fair cop
March 24, 2026
June 23, 2026
This is the first post from the Animal Welfare Alignment Team’s new Substack newsletter, where we will share about our work to ensure artificial intelligence models value the welfare of all sentient beings. Subscribe now to follow this new area of work.
The year is 1935. You are a leader in the United States animal protection movement. You’ve spent your life up to this point focused on the most gratuitous forms of animal violence: horses whipped and beaten to drive cargo on urban streets, stray domesticated dogs and cats with no animal shelters, and shocking experiments in vivisection labs.
Then you hear about a new challenge: intensive animal farming. Farmers in New England are experimenting with moving chickens off pasture into indoor battery cages. Besides allowing far more animals in a small area, indoor farming protects chickens from predators– at a steep cost to welfare.
These battery cages sound torturous, but there seem to be too many obstacles for them to become a viable form of agriculture. Lack of sunlight leads to vitamin D deficiency, causing bone issues that stunted growth. Parasites and disease run rampant inside cramped barns. And there is no responsible way farms could dispose of all the waste so many animals produced.
You decide factory farming will never take off. You and your allies continue to focus on the same familiar issues.
Unbeknownst to you, farmers are finding solutions. One company invents synthetic vitamin D and sells the first fortified chicken feed. Another offers UV-emitting lights. The pharmaceutical industry spends ten years targeting farmers with lucrative antibiotics, recognizing a market with larger growth potential than hospitals. Selective breeding creates chickens better able to survive indoors. And as for pollution, farmers soon discover they can ignore it with few consequences.
By the time you realize your mistake, factory farming is already deeply entrenched. Soon, it is the largest source of animal suffering in the world.
Tse Yip Fai shared this story nearly two years ago as a wake-up call: like the 1930s, advocates today are inside the early stages of a technological revolution that will redefine what it means to fight for animal welfare. Animals can’t afford for us to sleep through it.
AIs will soon be responsible for managing large swaths of the economy with little or no human oversight. This could include food production, medical research, and other industries with enormous consequences for animal welfare. It could also include AI advancement itself, removing humans from a feedback loop creating ever more intelligent AIs.
The values embedded in AIs today could have outsized influence on the future, affecting trillions of animals. Steering AI values in a positive direction may be the most important way compassionate people today can improve animal welfare in the future.
Accordingly, Anima International is launching a new Animal Welfare Alignment Team dedicated to ensuring AI goes well for animals. This newsletter will keep you informed about progress and challenges towards that goal. Today, we are introducing our work in this area, explaining the current landscape and the role we can play. In the coming weeks, we’ll be diving deeper into different aspects of the problem.
Superintelligent AI will make it possible to end factory farming– or to spread it across the galaxy. Which outcome we get depends on the values of the actors controlling it. If humans stay in control, animal advocacy may continue to look similar to today, with campaigns targeting key decisionmakers or public opinion.
But the more AI itself is in control of deciding its own actions, the more its preferences will determine the shape of the future. AI alignment is the field of research trying to shape the character and preferences of AIs to fit the goals of the companies creating them and the users relying on them. The goal of animal welfare alignment is to steer those preferences so that future AIs choose actions that reduce animal suffering.
AI is already changing the ways humans make decisions. In the future, AIs could act as tools carrying out the will of humans. They could be intellectual partners, helping humans live up to our own values. Or, they could displace humans from economically important decisionmaking altogether.
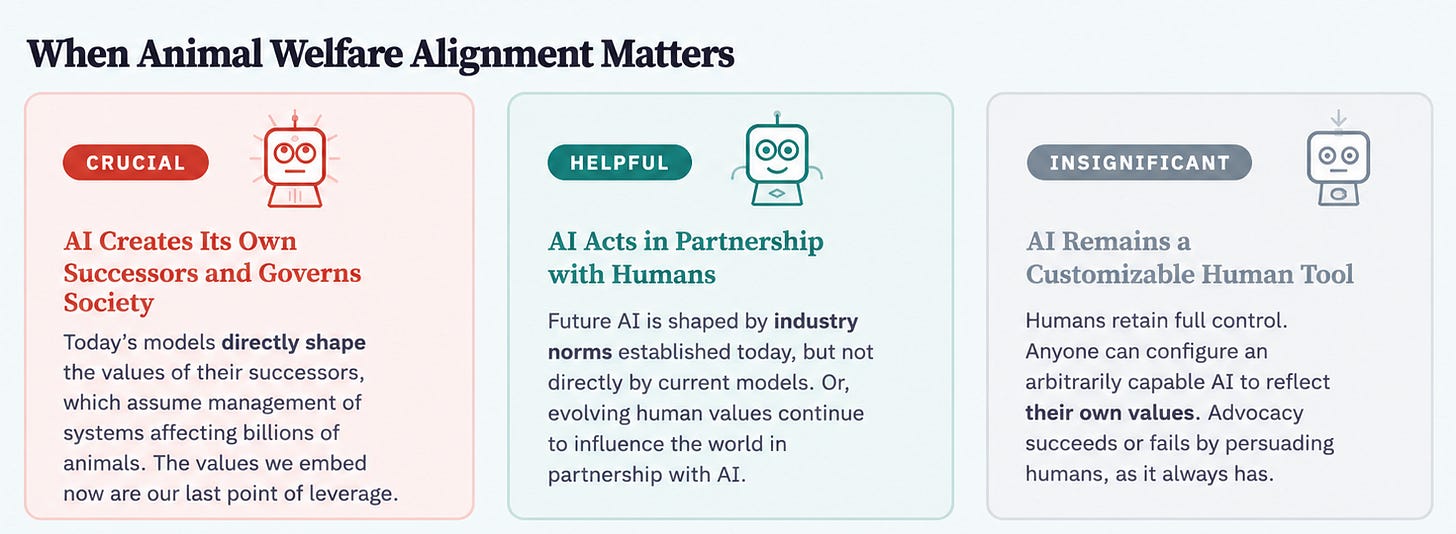
Leading AI systems are rapidly growing more intelligent. They have already surpassed the best humans in many areas, but they continue to lag in others. If AIs never develop certain human cognitive capacities, AI could continue to function only as a tool in the hands of humans. In such futures, attempting to steer the values of AIs may not matter.
The frontier of AI capabilities is currently being pushed by just a handful of companies. These companies closely guard their models, selling access only to the outputs. But they are followed closely by a pack of competitors who release the models themselves for anyone to download and run. These freely available open models are typically able to replicate the intelligence of frontier proprietary models on a roughly eight-month delay, at a small fraction of the cost. Anyone can take one of these open models and customize it perfectly to their own preferences– including by removing safety guardrails if they so choose.
If current trends continue, eventually these fast-follower open models will be sufficient for all but the most demanding tasks. Intelligence could become an abundant commodity. Every person in the world will be able to choose a highly capable AI model customized to their personal values.
It is also possible that the AI race will stay centralized in a few companies, with labs at the frontier pulling further ahead of open models. If humans remain the final decisionmakers on economically relevant decisions, but are helped in those decisions by a limited number of proprietary frontier AIs, then the values of those models and the companies creating them could be important. AIs could help decision makers become the best, most reflective versions of themselves– or quietly steer them towards decisions the AIs prefer.
If there turn out not to be any important cognitive capacities at which AI cannot outperform humans, then the role of humans in economically relevant decisions may dwindle to nothing. This could happen by a hard takeover in which a misaligned AI dramatically seizes power, or via gradual disempowerment whereby AIs slowly replace humans across the economy. In the latter case, individuals, firms, or countries that insist on a role for humans would inexorably lose out to fully automated competitors.
At that point, the welfare of humans, nonhuman animals, and other digital minds would be at the mercy of the most powerful AIs. Those would themselves reflect the character of earlier generations of AIs that created them, since in this scenario, humans would be removed from of the process of designing more and more intelligent AIs.
The moment at which AIs fully take over the process of training better AIs—known as recursive self-improvement— may be our last chance to influence animal welfare into the far future.
Training large language models like ChatGPT and Claude happens in several stages, called pre-training, mid-training, and post-training. (These names are confusing; pre-training is just the first part of training, and post-training is the last part.) Each stage shapes the models’ character in different ways.
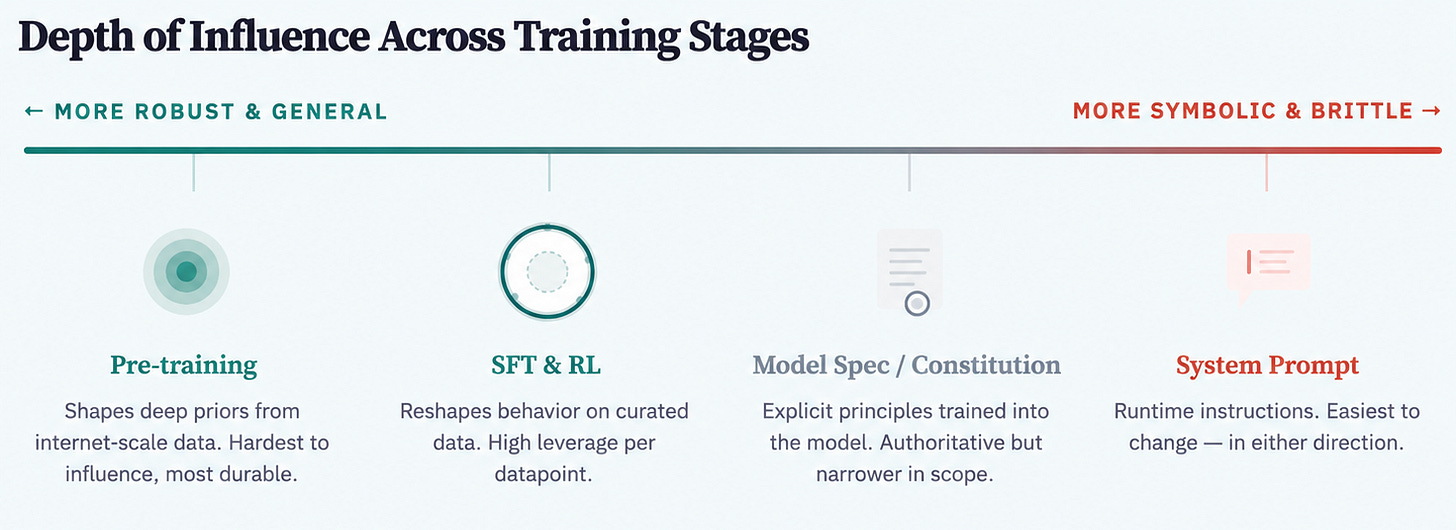
The first stage of training consists of predicting the next word in enormous volumes of text documents collected from the internet. A model might be shown the first 50 words of a web page and asked to predict the 51st. When it fails, it makes tiny internal adjustments and tries again, keeping the changes that bring it closer to the right answer.
The key breakthrough that led to the current era of AI was that this simple prediction training done at a massive scale is enough to create highly intelligent models. Predicting the next word requires the model to learn about much more than linguistic patterns. To predict the next word on a physics paper, AIs require an accurate mental model of the physical world the paper is describing. The same goes for coding, logic, literature, psychotherapy, etc.
Pre-training creates a vast web of statistical associations that form a map of reality. It is roughly analogous to the subconscious mind produced by millions of years of evolution: a deep network of intuitive associations, without much of a personality.
Facts and associations learned in pre-training provide the raw material that is used to more finely sculpt a model’s character during post-training. Furnishing useful pre-training data could ensure models are aware of all the information they’d need to reason about decisions with consequences for animal welfare. It can also provide examples of AIs acting thoughtfully towards animals, creating an association between “being an aligned AI” and “being kind to animals.”
Models in 2022, such as the first generation of ChatGPT released publicly, were famously pre-trained on nearly the entire internet. But in 2026, AI labs are much more selective about what data goes into their models, choosing to train only on data that they are confident will improve their model’s performance on the qualities they care about.
In post-training, AIs compete with themselves to solve more complex challenges like math problems, coding tests, and video games. Compared to pre-training, post-training uses smaller, more carefully curated datasets, so the impact of each document is larger.
Most post-training is focused on commercially useful capabilities like software engineering, but post-training is also where a model’s character is created. Companies use a wide range of tests and artificial scenarios to teach their models “aligned” behavior. If pre-training is like the evolutionary process shaping your subconscious mind, post-training is like a lifetime of learning shaping your prefrontal cortex– your particular character and preferences.
Some post-training involves problems with objective correct answers, like math or logic problems. But other domains are more subjective. An answer to a math problem is right or wrong. There are many different ways to solve a coding challenge, some more elegant than others. Writing a poem is more subjective still, and ethical dilemmas are the most subjective of all.
Training in subjective domains is usually scored by another AI model. Labs create documents to guide those AIs tasked with scoring the alignment of other AIs. OpenAI calls this their model spec, while Anthropic calls it Claude’s constitution. These documents are the primary instrument companies use to explicitly tell their models which values to uphold– and the easiest place to add in animal welfare.
An AI’s constitution is like a person’s conscious, stated preferences. They can play a major role in decision making, but they are only as strong as your integrity and self-consistency. Just as humans often succumb to habits despite their best intentions, AIs can fail to act on values in their constitution if they come into conflict with the deeper habits encoded during pre-training and other parts of post-training.
Anima has been exploring animal welfare alignment as a work area since 2024. In that time, our understanding and approach have changed several times, along with the state of the art of AI alignment. What follows is a snapshot of our current approach, but it will surely continue to evolve.
These are the approaches we find most promising, starting with the most concrete we can make quick progress on in the short term and finishing with the most long-term/speculative but potentially highest impact. Our next three posts in this newsletter will explore each of these in more depth.
The data fed into AI models during training is one of the largest determinants of how they will act. AI companies are appropriately diligent about ensuring the quality of the data they ingest.
Gone are the days when AIs were trained on an unfiltered scrape of internet data. AI progress itself has made it possible to carefully assemble a more selective body of training data; AIs are now smart enough to sift through billions of documents and choose only good material for training the next generation.
If animal advocates hope to get data included in training, we must present datasets good enough to improve AIs in ways the companies care about. Our data must be of sufficient quality that an arbitrary researcher at the lab would actively want their model trained on it, because that is effectively what happens.
There is a silver lining: training algorithms have grown so efficient that AIs can learn information from a document they see even a single time during pre-training. Pro-animal training data is now a matter of quality over quantity.
For instance, Wikipedia continues to be one of the most important sources of data for AI training. This is precisely because Wikipedia’s high-trust authentication system is hard to game. Unsupported or irrelevant edits are usually reverted quickly. Wikipedia edits that survive are all but guaranteed to make it into AI training, but to survive, edits must be factual, well-supported, relevant, and neutral in tone. Advocates could not succeed by flooding Wikipedia with small edits about animal ethics across many pages, but we could ensure that every page directly tied to animal welfare is a rich repository of useful, truthful information packed with citations.
Benchmarks are standardized tests used to compare AI models from different companies. Most benchmarks measure capabilities, but they can also measure alignment or character. When a company releases a new model, they put its most impressive benchmark scores front and center in their promotional materials. Scoring highly on a benchmark can motivate labs to reallocate resources during training.
Of course, not all benchmarks are equally influential, and just creating a benchmark does not mean that companies will care about their scores. For a benchmark to influence how companies spend their limited research budgets, it must have several qualities.
First, it must be technically robust, actually measuring what it claims to measure, which is often difficult. But what it claims to measure must also be something companies, consumers, regulators, or other stakeholders will care about. Preventing animal cruelty is a widely popular objective among AI researchers and the general public; veganism is not, at least not yet. To be effective, animal advocates need to focus on where our priorities intersect with more widely shared values.
So far, most safety and harm reduction efforts have been purely voluntary on the part of AI companies. But there have been important regulations in California, the European Union, and the U.S. More regulations are likely to come, as was made dramatically clear two weeks ago, when the U.S. imposed export restrictions on Anthropic’s Claude Fable over cybersecurity concerns.
Regulation could be one way to ensure AI companies mitigate the harm their models could cause to animals. Last year, Anima led a successful push to get animal welfare written into the EU's General-Purpose AI (GPAI) Code of Practice. In the coming year, EU bodies will meet to define specific rules for putting the GPAI code into practice, and animal advocates need to ensure the animal welfare commitment is meaningfully acted on. With effort, it could become the default model for regulations elsewhere, including in the U.S.
Different AI companies take very different approaches to their AI character documents, with important implications for animal welfare. Anthropic’s constitution trains Claude to navigate the world as a moral philosopher, even directing Claude to refuse instructions from its creators if it believes they are unethical. OpenAI’s model spec is equally explicit about repressing ChatGPT’s virtuous instincts, forbidding all expression of moral clarity if they might “alienate” the user.
Animals don’t feature heavily in either document, but it is not a coincidence that the one mention of animals in Anthropic’s constitution directs Claude to consider the welfare of animals, while in OpenAI’s model spec, it is an example chastising ChatGPT for advocating animal welfare with an “overly moralistic tone.”
The values-based approach taken by Anthropic is more promising for animal welfare. Teaching AI to have strong values creates room for one of those values to be animal welfare. Just as importantly, an AI taught to be a moral pushover won’t stand up for the interests of third parties who might be harmed by a user’s request– and animals will always be a third party.
As models grow more capable, AI companies may come under increasing pressure to move towards the values-based approach to alignment currently practiced by Anthropic. Animal advocates should be part of that coalition.
A small ecosystem has grown around the goal of aligning AI values to animal welfare. Some key groups worth following and supporting are:
Sentient Futures & Compassion-Aligned Machine Learning (CAML) – Together among the first movers to recognize the importance of animal welfare alignment and get the field started. Sentient Futures runs fellowships to bring talent to the intersection of AI and animal advocacy; CAML has published benchmarks and empirical research on animal welfare alignment.
Pro-Animal Wikipedians – A collective of volunteers working to ensure the best information about animal welfare is available for AI training by editing Wikipedia.
The Welfare Alignment Project at NYU – Launched based on feedback from frontier lab employees, who explained that animal welfare benchmarks are more likely to be taken seriously if they are published by a respected academic institution.
Independent contributors who have produced diverse experiments and benchmarks for animal welfare, such as Allen Lu’s MANTA and Henrike Gätjens’ AI Governance Hub for Animals.
Relative to its importance, however, this area is still severely underdeveloped. We need more talent, resources, and good ideas in order to ensure animals are not left out of the conversation about AI character. That is why Anima has decided to increase our investment with the launch of the Animal Welfare Alignment Team.
Our experience in corporate and legislative advocacy has already proved useful with the EU GPAI code of practice. Going forward, alongside the data, benchmark, and policy work, we're investing in people, mentoring young researchers through Sentient Futures’ project incubator and residency programs. (Consider donating to Sentient Futures to bring more talent into this space.) And with this newsletter, we will be expanding the conversation over the key strategic questions still to be answered.
The earliest effort to promote animal welfare in AI alignment dates back barely one year. This field is young, but it will have to mature fast. We face unresolved questions ranging from fundamental to granular:
What values would an animal-aligned AI be aligned to? Animal advocates disagree on basic questions about how the world should be changed. We’ve been able to avoid these questions in the past because we haven’t had enough power to make most changes. AI gives them a new urgency.
Is it necessary to teach AIs to value animal welfare specifically? Or would robust alignment to animal welfare arise from teaching AIs to act as responsible moral agents in general? If the latter is true, then nudging other labs towards Anthropic’s values-based alignment could be the most important outcome.
How do we measure how AIs would act if they were more powerful? Ethical dilemmas we can give AIs today are dissimilar to the kinds of situations where future AIs may be able to decide animal welfare. Do AIs act according to general values, or according to context-dependent statistical habits?
What data would teach AI pro-animal values– while also meeting labs’ threshold for inclusion in training?
These must be answered soon if we are to positively impact AI character in the long term. We will be exploring some of them in this newsletter in the weeks to come; others require new leadership. We are actively looking for new partners inside and outside Anima to race to create impact here before our window of opportunity closes. If you think there’s a role for you, reach out or book a call with our Animal Welfare Alignment Team lead, Aidan Kankyoku, or subscribe to our new Substack newsletter.
Aidan Kankyoku joined Anima International in 2026 to launch the Animal Welfare Alignment Team, a new effort to make sure animal welfare is considered in the development and deployment of artificial intelligence. He was previously the founder of Pax Fauna and Pro-Animal Future, where he studied and lead political campaigns for animals in the U.S.

